Linux Kernel 内核同步之 RCU
尽管 rwlock 相对于 spinlock 做了很大的改进,rwlock 允许多个读者同时并发访问。但是进行写操作时,仅有一个写者具有访问权限,读者不可访问。RCU 进一步改善了这个问题,其允许多个读者和写者并发执行。而且 RCU 是不使用锁的,其对读者几乎没有限制,访问效率极高。本文简单概述这项技术。
一、RCU 核心思想
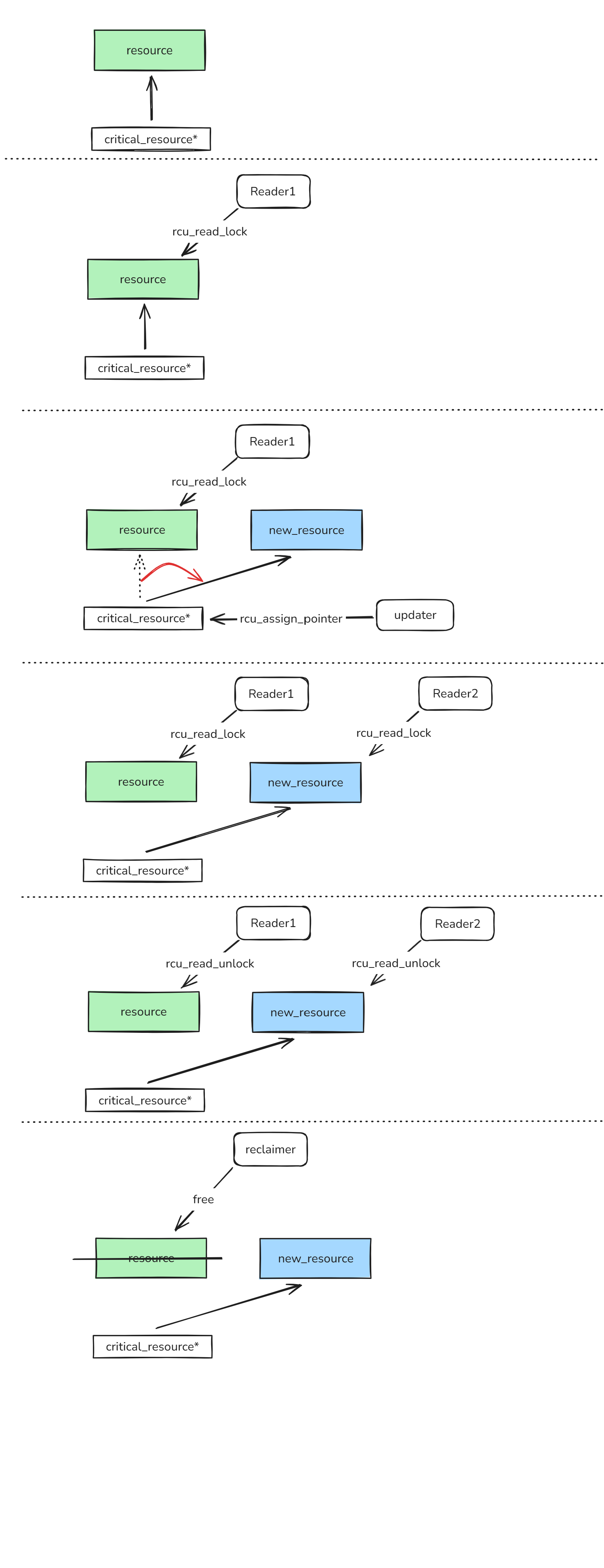
读者无锁(Read),写者副本(Copy),延迟释放(Update)。
读者:
- 调用
rcu_read_lock()/rcu_read_unlock()包裹访问区域。 - 读操作只需简单的内存屏障,不加锁,非常快,不会阻塞。
写者:
- 写操作流程是 复制-修改-替换:
- 分配一份新的数据副本,在新副本上修改。
- 使用
rcu_assign_pointer()替换全局指针,让读者开始访问新版。
回收:
- 旧版本不能立刻释放,因为可能仍有读者在
rcu_read_lock()临界区访问它。 - 写者调用
call_rcu()或synchronize_rcu(),通知系统在 宽限期(grace period) 结束后释放旧版本。 - 宽限期保证:所有读者都退出了临界区 → 没有线程再访问旧版本。
基于 RCU 的工作原理,RCU 只保护被动态分配并且通过指针引用的数据结构。
二、RCU core API
The core RCU API is quite small:
- Updateer
rcu_assign_pointer
struct foo {
int a;
int b;
int c;
};
struct foo *gp = NULL;
/* . . . */
p = kmalloc(sizeof(*p), GFP_KERNEL);
p->a = 1;
p->b = 2;
p->c = 3;
gp = p;
根据优化和内存屏障部分我们知道 11 12 13 14 行代码不一定按照我们想要的顺序执行,其很有可能先执行 14 行,再依次赋值。因此我们需要内存和优化屏障。Linux Kernel 已经封装了 rcu_assign_pointer 帮我们实现上述过程。其能保证下面代码先赋值 abc 结束后,再对 gp 赋值。
p->a = 1;
p->b = 2;
p->c = 3;
rcu_assign_pointer(gp, p);
rcu_read_lockrcu_read_unlockrcu_dereference
p = gp;
if (p != NULL) {
do_something_with(p->a, p->b, p->c);
}
同样,我们在读取端也要有类似的操作,同时读取端还要通过上锁,保证访问内容暂时不要被回收(旧作业)。
rcu_read_lock();
p = rcu_dereference(gp);
if (p != NULL) {
do_something_with(p->a, p->b, p->c);
}
rcu_read_unlock();
synchronize_rcucall_rcu用于回收旧资源,启用synchronize_rcu是同步,其会 block 等待旧资源上所有的锁都释放,call_rcu是异步。
三、RCU 基本流程
Ref
[1] What is RCU? – “Read, Copy, Update” https://www.kernel.org/doc/html/next/RCU/whatisRCU.html
[2] What is RCU, Fundamentally? https://lwn.net/Articles/262464/