Linux Kernel 内核同步之优化和内存屏障
Linux Kernel 是支持优化屏障和内存屏障的,其中优化屏障是针对编译器而言的,内存屏障是针对处理器而言的,因此内存屏障取决于处理器架构。本文以 ARMv8 架构处理器从下向上讲解内存屏障,并简述优化屏障。
一、Linux Kernel 优化屏障
编译器在编译源代码时会考虑性能进行优化重新排序指令顺序,以下面代码为例:
volatile int a = 0;
volatile int b = 0;
void no_barrier() {
a = 1;
b = 2;
}
void with_barrier() {
a = 1;
asm volatile("" ::: "memory"); // 编译器优化屏障
b = 2;
}
aarch64-none-linux-gnu-gcc -S test.c -O3 -o test.s
no_barrier:
.LFB0:
.cfi_startproc
adrp x0, .LANCHOR0
add x1, x0, :lo12:.LANCHOR0
mov w3, 1
mov w2, 2
str w3, [x0, #:lo12:.LANCHOR0]
str w2, [x1, 4]
ret
.cfi_endproc
with_barrier:
.LFB1:
.cfi_startproc
adrp x0, .LANCHOR0
mov w2, 1
add x1, x0, :lo12:.LANCHOR0
str w2, [x0, #:lo12:.LANCHOR0]
mov w0, 2
str w0, [x1, 4]
ret
.cfi_endproc
我们只需观察 mov str 指令的顺序:
no_barrier情况下是往两个寄存器中存值,再统一存储到内存中。mov-mov-str-strwith_barrier情况下是一个接一个存储到内存中。mov-str-mov-str
优化屏障是针对编译器而言,我们可以在 compiler.h 中找到 kernel 提供的优化屏障宏 barrier()
// include/linux/compiler.h
/* Optimization barrier */
#ifndef barrier
/* The "volatile" is due to gcc bugs */
# define barrier() __asm__ __volatile__("": : :"memory")
#endif
二、内存屏障
现代处理器普遍采用超标量(superscalar)[1]架构、 乱序执行(out-of-order execution)[2] 等技术来提高指令级并行效率,因此指令的执行顺序在处理器流水线中很可能被打乱,与程序代码编写时的序列不一致。
在一个单处理器系统里面,不管 CPU 怎么乱序执行,它最终的执行结果都是程序员想要的结果,也就是类似于顺序执行模型。但是在多核处理器系统中,一个 CPU 内核中内存访问的乱序执行可能会对系统中其他的观察者(例如其他内核)产生影响,即它们可能观察到的内 CPU 存执行次序与实际执行次序有很大的不同,特别是多核并发访问共享数据的情况下。
对此,引出存储一致性问题,即系统中所有处理器所看到的对不同地址访问的次序问题。
不再对理论详细展开,我们可以概括出两点:
- 指令的执行顺序在处理器中很有可能被打乱
- 乱序执行在单处理器系统中不会有问题。在多核处理器系统中,多核并发访问共享数据会有问题
这里不对相关理论知识进行展开,感兴趣的读者可以在 Refercences [2] 中找到一些理论知识。
抽象出下面的一个系统模型为例子 [3] 并举例说明乱序带来的影响:
: :
: :
: :
+-------+ : +--------+ : +-------+
| | : | | : | |
| | : | | : | |
| CPU 1 |<----->| Memory |<----->| CPU 2 |
| | : | | : | |
| | : | | : | |
+-------+ : +--------+ : +-------+
^ : ^ : ^
| : | : |
| : | : |
| : v : |
| : +--------+ : |
| : | | : |
| : | | : |
+---------->| Device |<----------+
: | | :
: | | :
: +--------+ :
: :
假设 CPU 流水线上的指令序列如下:
{count = 0 flag = false}
CPU 1 | CPU 2
=============== | ===============
count=1; | while(!flag){
等待
| }
flag=true; | assert(count= == 1)
理想状态下,CPU 2 断言要是成功的,因为在 CPU 1 端是先置 count 在置 flag。但是现代多核系统中,CPU 1 会对两条指令重排来提升性能。因为在 CPU 1 看来,先执行 flag=true 对其结果是没有影响的。
因此我们需要一条强制的指令(内存屏障指令)来告诉 CPU : 所有在屏障之前的内存读/写操作,必须在屏障之后的所有内存读/写操作开始之前,全部完成,并且其结果对其它核心可见。
三、ARM64 中的内存屏障指令
ARM64 处理器采用弱一致性内存模型,在该内存模型下,CPU的加载和存储访问的序列有可能和程序中的序列不一致。因此 ARM64 处理器使用内存屏障指令实现同步访问,内存屏障指令有以下原则:
- 在内存屏障指令后面的所有数据访问必须等待内存屏障指令
- 多条内存屏障指令顺序执行
ARMv8 指令级提供了 3 条内存屏障指令:
- 数据内存屏障(Data Memory Barrier, DMB)指令:仅当所有在它前面的内存访问(读/写)操作都执行完毕后,才提交(commit)在它后面的访问指令。
- 数据同步屏障(Data Synchronization Barrier, DSB)指令:比 DMB 严格,仅当所有在它前面的内存访问(读/写)指令都执行完毕后,才会执行后面的指令,即任何指令都要等待 DSB 指令前面的内存访问指令完成。
- 指令同步屏障(Instruction Synchronization Barrier, ISB)指令:确保所有在 ISB 指令之后的指令都从指令高速缓存或内存中重新获取。
DMB 和 DSB 内存屏蔽指令
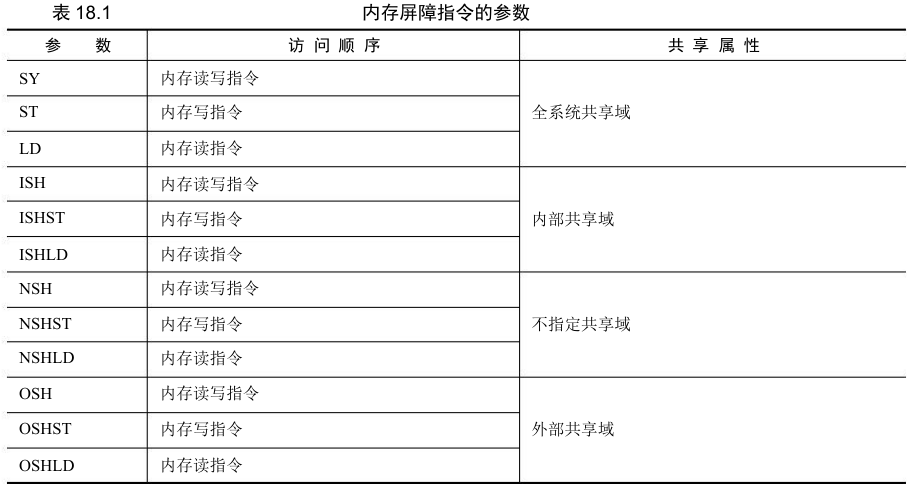
DMB 和 DSB 指令后面可以带参数,用于指定共享属性域以及具体的访问方向。
ARMv8 定义了 4 种域:
- 全系统共享(full system sharable)域
- 外部共享(outer sharable)域
- 内部共享(inner sharable)域
- 不指定共享(non-sharable)域
访问方向有 3 种:
- 读内存屏障:在内存屏障指令之前的所有加载指令必须完成,但是不需要保证存储指令执行完。在内存屏障指令后面的加载和存储指令必须等到内存屏障指令执行完
- 写内存屏障:仅仅影响存储操作,对加载操作没有约束
- 读写内存屏障:在内存屏障指令之前的所有读写指令必须在内存屏障指令之前执行完
结合上述供组合成 4x3=12 种参数:
ISB 内存屏障指令
ISB 指令会冲刷流水线,然后从指令高速缓存或者内存中重新预取指令。
四、Linux Kernel 内存屏障
// include/asm-generic/barrier.h
/*
* Architectures that want generic instrumentation can define __ prefixed
* variants of all barriers.
*/
#ifdef __mb
#define mb() do { kcsan_mb(); __mb(); } while (0)
#endif
#ifdef __rmb
#define rmb() do { kcsan_rmb(); __rmb(); } while (0)
#endif
#ifdef __wmb
#define wmb() do { kcsan_wmb(); __wmb(); } while (0)
#endif
#ifdef __dma_mb
#define dma_mb() do { kcsan_mb(); __dma_mb(); } while (0)
#endif
#ifdef __dma_rmb
#define dma_rmb() do { kcsan_rmb(); __dma_rmb(); } while (0)
#endif
#ifdef __dma_wmb
#define dma_wmb() do { kcsan_wmb(); __dma_wmb(); } while (0)
#endif
// arch/arm64/include/asm/barrier.h
#define isb() asm volatile("isb" : : : "memory")
#define dmb(opt) asm volatile("dmb " #opt : : : "memory")
#define dsb(opt) asm volatile("dsb " #opt : : : "memory")
#define __mb() dsb(sy)
#define __rmb() dsb(ld)
#define __wmb() dsb(st)
#define __dma_mb() dmb(osh)
#define __dma_rmb() dmb(oshld)
#define __dma_wmb() dmb(oshst)
#define __smp_mb() dmb(ish)
#define __smp_rmb() dmb(ishld)
#define __smp_wmb() dmb(ishst)
TODO: READ_ONCE() WIRTE_ONCE()
TODO:dmb_mb 等用法
References
[1] Superscalar processor - Wiki https://en.wikipedia.org/wiki/Superscalar_processor
[2] Out-of-order execution - Wiki https://en.wikipedia.org/wiki/Out-of-order_execution
[3] Kernel Documentation memory-barriers.txt https://www.kernel.org/doc/Documentation/memory-barriers.txt